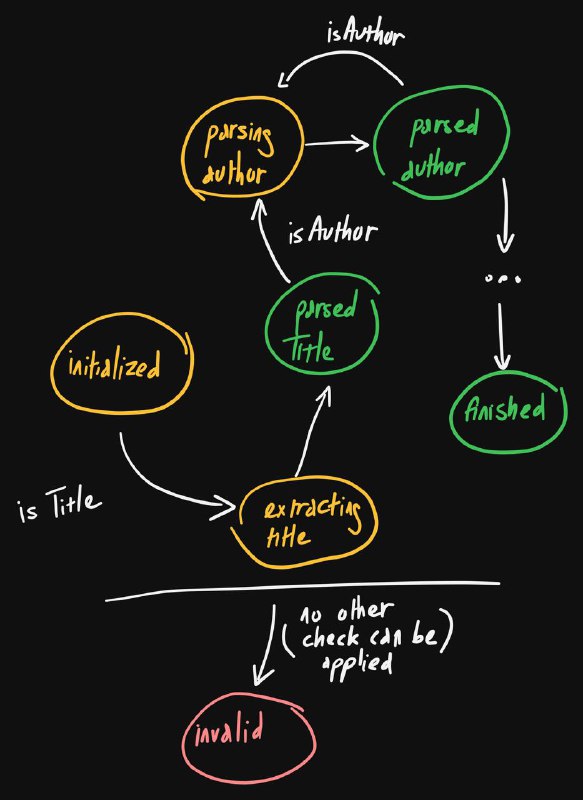
💡Парсинг неструктурированных DOCX в TypeScript/Node.js: как я решил нетривиальную задачу
Недавно я взял фриланс-проект, где нужно было преобразовать «почти неструктурированные» DOCX-файлы в структурированные данные, например, в JSON. Сначала я думал, что справлюсь за пару дней. Но в итоге потратил больше пяти.
📄Что такое «почти неструктурированные» DOCX?
Файлы генерируются сервером и содержат несколько статей. Каждая статья обычно включает заголовок, автора, дополнительную информацию и резюме. Однако структура варьируется: где-то нет автора, где-то несколько, а вместо резюме — комментарии.
🔍Проблемы с существующими библиотеками:
* officeparser: извлекает только текст, без структуры. * docx4js: не имеет типов для TypeScript и сложно использовать. * docx: больше подходит для создания DOCX, а не для парсинга.
🛠️Моё решение:
Поняв, что DOCX — это ZIP-архив с XML-файлами, я решил сам обработать document.xml. Использовал fast-xml-parser для преобразования XML в JS-объекты. Однако структура XML оказалась сложной, и пришлось разбираться в ней вручную.
📌Вывод:
Иногда проще написать свой парсер, чем пытаться адаптировать существующие решения. Особенно когда структура данных нестабильна и требует гибкого подхода.
💡Парсинг неструктурированных DOCX в TypeScript/Node.js: как я решил нетривиальную задачу
Недавно я взял фриланс-проект, где нужно было преобразовать «почти неструктурированные» DOCX-файлы в структурированные данные, например, в JSON. Сначала я думал, что справлюсь за пару дней. Но в итоге потратил больше пяти.
📄Что такое «почти неструктурированные» DOCX?
Файлы генерируются сервером и содержат несколько статей. Каждая статья обычно включает заголовок, автора, дополнительную информацию и резюме. Однако структура варьируется: где-то нет автора, где-то несколько, а вместо резюме — комментарии.
🔍Проблемы с существующими библиотеками:
* officeparser: извлекает только текст, без структуры. * docx4js: не имеет типов для TypeScript и сложно использовать. * docx: больше подходит для создания DOCX, а не для парсинга.
🛠️Моё решение:
Поняв, что DOCX — это ZIP-архив с XML-файлами, я решил сам обработать document.xml. Использовал fast-xml-parser для преобразования XML в JS-объекты. Однако структура XML оказалась сложной, и пришлось разбираться в ней вручную.
📌Вывод:
Иногда проще написать свой парсер, чем пытаться адаптировать существующие решения. Особенно когда структура данных нестабильна и требует гибкого подхода.
China’s stock markets are some of the largest in the world, with total market capitalization reaching RMB 79 trillion (US$12.2 trillion) in 2020. China’s stock markets are seen as a crucial tool for driving economic growth, in particular for financing the country’s rapidly growing high-tech sectors.Although traditionally closed off to overseas investors, China’s financial markets have gradually been loosening restrictions over the past couple of decades. At the same time, reforms have sought to make it easier for Chinese companies to list on onshore stock exchanges, and new programs have been launched in attempts to lure some of China’s most coveted overseas-listed companies back to the country.
That strategy is the acquisition of a value-priced company by a growth company. Using the growth company's higher-priced stock for the acquisition can produce outsized revenue and earnings growth. Even better is the use of cash, particularly in a growth period when financial aggressiveness is accepted and even positively viewed.he key public rationale behind this strategy is synergy - the 1+1=3 view. In many cases, synergy does occur and is valuable. However, in other cases, particularly as the strategy gains popularity, it doesn't. Joining two different organizations, workforces and cultures is a challenge. Simply putting two separate organizations together necessarily creates disruptions and conflicts that can undermine both operations.